面试准备之八股文

1. 数据结构和算法
1.1 在微服务架构中遇到过哪些挑战?
- 服务间通信的问题:
在微服务架构中,各个服务之间要进行相互的通信,服务间通信的可靠性,延迟和错误处理都需要考虑
- 解决方案:
- 通过API网关来进行路由请求的管理
- 消息队列:通过消息队列进行异步通信
- 通信失败后的重试机制
- 数据一致性:
在分布式的系统中保证数据一致性比较复杂
- 解决方案:
- 最终一致性:而不是强一致性,通过异步处理和补偿机制来达到数据一致性
- 幂等操作:每个请求携带唯一的ID,保障相同请求只处理一次
- 分布式锁
- 分布式事务(2PC两阶段提交,3PC三阶段提交)
- 监控和调试
- 运维和部署
1.2 布隆过滤器的使用场景
- 如果面试的问题是黑名单,并且允许出错。可以使用布隆过滤器解决
- 使用位图作为存储的数据结构,可以节省空间
- 先初始化一个m长度的位图
- 对数据进行k次哈希函数,然后对m取模,得到一个index
- 将这个index设置为1
2. 数据库相关
2.1. 什么场景下索引会失效
- 使用 % like查询时
- 使用不等于(!= <>)操作符
- 类型隐转
- 比如没有按照索引字段的类型传入,比如索引类型是字符串,传入的是数字
- 未满足最左匹配要求
- 比如一个复合索引(a,b,c),如果直接搜索where b = xx的时候就会失效
- 是因为b+树存储复合索引的时候是按照索引的顺序保存的,如果没有前置条件无法快速查询到索引
2.2. 基于Redis的分布式锁会有什么问题?
- 在高并发环境下,可能会出现性能问题:尽量减少锁的获取和释放次数
- 如果客户端失去连接等情况下可能出现锁锁失效的问题:锁续期
2.3. 如何基于Redis锁进行续期?
获取锁:使用
SET命令获取锁,并设置锁的过期时间。启动续期线程:在获取锁之后,启动一个专门的线程或任务来定期续期锁。
定期续期:在续期线程中,定期检查锁的状态,并在锁即将过期时,延长锁的过期时间。
释放锁:在任务完成后,释放锁,并停止续期线程。
2.4. Redis主从模式,集群模式和哨兵模式的区别
1. 主从模式 (Master-Slave Mode)
特点
- 主节点Master:负责处理所有的写操作。
- 从节点Slave:负责处理读操作,并从主节点同步数据。
- 数据同步:从节点会定期从主节点同步数据,以保持数据的一致性。
优点
- 读写分离:可以通过增加从节点来扩展读操作的能力。
- 简单实现:配置相对简单,适用于小规模应用。
缺点
- 单点故障:如果主节点故障,整个系统的写操作会中断,除非手动进行故障转移。
- 一致性问题:从节点的数据可能会有延迟,不适合对一致性要求很高的场景。
2. 集群模式 (Cluster Mode)
特点
- 分片Sharding:数据根据哈希槽分布在多个节点上,每个节点负责一部分数据。
- 高可用性:每个节点都有一个或多个从节点,主节点故障时从节点可以自动提升为主节点。
- 自动故障转移:集群模式内置了故障检测和自动故障转移机制。
优点
- 水平扩展:可以通过增加节点来扩展存储容量和处理能力。
- 高可用性:自动故障转移机制保证了系统的高可用性。
缺点
- 复杂性:配置和管理相对复杂,需要更多的运维工作。
- 数据迁移:在扩展或缩减集群时,数据迁移可能会影响性能。
3. 哨兵模式 (Sentinel Mode)
特点
- 监控:哨兵节点监控主从节点的运行状态。
- 自动故障转移:主节点故障时,哨兵会自动提升一个从节点为新的主节点。
- 通知:哨兵可以通知客户端新的主节点地址。
优点
- 高可用性:自动故障转移机制保证了系统的高可用性。
- 监控和通知:提供了对 Redis 实例的监控和通知功能。
缺点
- 复杂性:需要配置和管理哨兵节点,增加了系统的复杂性。
- 一致性问题:在故障转移期间,可能会有短暂的不可用时间。
总结
- 主从模式适用于读多写少的场景,配置简单,但存在单点故障风险。
- 集群模式适用于需要高扩展性和高可用性的场景,适合大规模应用,但配置和管理复杂。
- 哨兵模式适用于需要高可用性和自动故障转移的场景,提供了监控和通知功能,但增加了系统的复杂性。
2.5. Redis持久化的方案是什么
1. RDB (Redis Database File)
RDB 是 Redis 的快照持久化方式,它会在指定的时间间隔内生成数据的快照并保存到磁盘上。
特点
- 性能高:RDB 文件是在后台生成的,不会影响 Redis 的性能。
- 恢复速度快:RDB 文件是二进制格式,加载速度快。
- 数据丢失风险:由于是定时快照,可能会丢失最后一次快照之后的数据。
配置
可以通过配置文件中的 save 选项设置 RDB 的保存策略,例如:
1 | save 900 1 # 900秒内至少有1次写操作 |
适用场景
- 数据丢失容忍度高:适用于对数据丢失容忍度较高的场景。
- 快速恢复需求:需要快速恢复数据的场景。
2. AOF (Append Only File)
AOF 是 Redis 的日志持久化方式,它会将每个写操作记录到日志文件中。
特点
- 数据安全性高:AOF 可以配置为每个写操作都同步到磁盘,确保数据不丢失。
- 文件大小可控:通过日志重写机制,可以控制 AOF 文件的大小。
- 恢复速度相对较慢:由于需要重放所有的写操作,恢复速度比 RDB 慢。
配置
可以通过配置文件中的 appendonly 选项启用 AOF:
1 | appendonly yes |
适用场景
- 数据丢失容忍度低:适用于对数据丢失容忍度低的场景。
- 高数据安全性需求:需要高数据安全性的场景。
3. 混合持久化 (RDB + AOF)
Redis 4.0 引入了混合持久化模式,结合了 RDB 和 AOF 的优点。在这种模式下,Redis 会在生成 RDB 快照的同时,记录 AOF 日志。
特点
- 数据安全性和恢复速度兼顾:既有 RDB 的快速恢复速度,又有 AOF 的高数据安全性。
- 文件大小适中:通过混合持久化,可以控制持久化文件的大小。
配置
可以通过配置文件中的 aof-use-rdb-preamble 选项启用混合持久化:
1 | aof-use-rdb-preamble yes |
适用场景
- 数据安全性和恢复速度并重:适用于需要兼顾数据安全性和恢复速度的场景。
4. 无持久化
在某些场景下,可能不需要持久化数据,例如缓存场景。
特点
- 性能最优:无需持久化操作,性能最高。
- 数据丢失风险高:服务器重启或故障时,数据会丢失。
适用场景
- 缓存应用:适用于缓存场景,对数据丢失不敏感。
2.6 InnoDB的结构是什么?一页的大小是多少?为什么这么设计?
- InnoDB采用了B+树作为数据存储的结构,搜索性能良好,支持事务和外键。支持行锁和表锁
- 一页设置为16KB
平衡I/O性能与存储效率:
- 16KB的页大小在大多数情况下能够提供较好的I/O性能和存储效率之间的平衡。较小的页大小可能会导致更多的I/O操作,而较大的页大小可能会浪费存储空间。
适应大多数工作负载:
- 16KB的页大小适用于各种类型的工作负载,包括读密集型和写密集型应用。它能够有效地缓存和管理数据页,从而提高数据库的整体性能。
减少碎片:
- 较大的页大小有助于减少存储碎片,因为更多的数据可以被紧凑地存储在单个页中,从而减少了磁盘上的不连续存储。
2.7 事务的隔离级别有哪些?
读未提交(Read Uncommitted):
- 特性:允许事务读取其他事务尚未提交的更改。
- 问题:可能会发生脏读(Dirty Read)。
- 应用场景:很少使用,适用于对一致性要求极低的场景。
读已提交(Read Committed):
- 特性:只允许事务读取其他事务已提交的更改。
- 问题:可能会发生不可重复读(Non-repeatable Read)。
- 应用场景:大多数数据库系统的默认隔离级别,适用于大部分应用场景。
可重复读(Repeatable Read):
- 特性:确保在同一事务中多次读取同一数据时,数据值保持一致。
- 问题:可能会发生幻读(Phantom Read)。
- 应用场景:适用于需要确保读取数据一致性的场景。
可串行化(Serializable):
- 特性:最高的隔离级别,完全锁定读取的行,防止其他事务进行插入、更新或删除操作。
- 问题:避免了脏读、不可重复读和幻读。
- 应用场景:适用于需要严格数据一致性且并发量较低的场景。
事务并发控制
- 如果不进行并发控制,可能会产生的现象
- 幻读(Phantom Read):一个事务第二次查出现了第一次没有的结果
- 非重复读(Nonrepeatable Read):一个事务重复读两次得到不同的结果
- 脏读(Dirty Read):一个输入读取到另一个事务没有提交的修改
- 修改丢失(Lost Update):并发写入造成其中一些修改丢失
2.8 MySQL的行锁如何实现?
MySQL 的行锁(Row Lock)主要在 InnoDB 存储引擎中实现,用于保证并发事务的隔离性和一致性。行锁的实现依赖于多版本并发控制(MVCC)和锁机制。以下是 InnoDB 行锁的实现原理和相关细节:
1. 行锁的类型
InnoDB 提供了两种主要的行锁类型:
- 共享锁(S 锁,Shared Lock):允许事务读取一行数据,防止其他事务修改该行。
- 排他锁(X 锁,Exclusive Lock):允许事务读取和修改一行数据,防止其他事务读取或修改该行。
2. 行锁的实现机制
InnoDB 的行锁是通过索引来实现的。这意味着只有通过索引条件检索数据时,InnoDB 才会使用行锁。如果没有使用索引,InnoDB 会退化为使用表锁。
- 索引锁定:InnoDB 会锁定索引记录来实现行锁。即使是对表的主键进行操作,InnoDB 也是通过锁定主键索引来实现行锁。
- 间隙锁(Gap Lock):在可重复读(REPEATABLE READ)隔离级别下,为了防止幻读,InnoDB 还会使用间隙锁。间隙锁锁定索引记录之间的间隙,防止其他事务在这些间隙中插入新记录。
- Next-Key Lock:这是行锁和间隙锁的组合,锁定一个索引记录以及其前后的间隙。
3. 行锁的操作
行锁主要通过以下 SQL 语句触发:
- SELECT … FOR UPDATE:对查询结果集中的每一行数据加排他锁。
- SELECT … LOCK IN SHARE MODE:对查询结果集中的每一行数据加共享锁。
- UPDATE、DELETE 和 INSERT:这些操作会自动对涉及的行加排他锁。
4. 行锁的管理
InnoDB 使用锁表(Lock Table)来管理行锁。锁表记录了当前所有的锁信息,包括锁类型、锁定的行、事务 ID 等。
- 锁等待:当一个事务试图获取一个已经被其他事务持有的锁时,会进入等待状态。
- 死锁检测:InnoDB 有死锁检测机制,会自动检测并解决死锁问题。解决办法通常是回滚其中一个事务。
5. 行锁的使用示例
假设有一个名为 users 的表:
1 | CREATE TABLE users ( |
以下是一些行锁的使用示例:
- 共享锁:
1 | START TRANSACTION; |
- 排他锁:
1 | START TRANSACTION; |
- 更新操作:
1 | START TRANSACTION; |
6. 注意事项
- 使用行锁时,确保查询条件使用索引,否则可能会导致表锁,影响并发性能。
- 尽量缩短事务的执行时间,减少锁的持有时间,避免长时间锁定导致的锁等待和死锁问题。
- 了解和配置合适的隔离级别,根据业务需求选择合适的锁策略。
通过这些机制,InnoDB 能够高效地管理并发事务,保证数据的一致性和隔离性。
2.9 如何设计使用一个乐观锁?
比如在一个审批的操作中,针对于审批的任务ID和version字段加锁。
先获取当前的task数据。
提交的时候判断当时的version是否等于获取到的version值,如果不一致,则不提交SQLUPDATE approval_tasks SET status = 'approved', version = version + 1 WHERE id = 1 AND version = 1;
1 | from flask import Flask, request, jsonify |
2.10 Redis为什么快
1. 使用内存
- 速度快,
- 高吞吐,低延迟
- 代码实现简单
2. 单线程
多线程的一些问题:
线程上下文切换/性能开销(锁)/复杂度
3. IO多路复用
- 不同IO模型的解释例子:
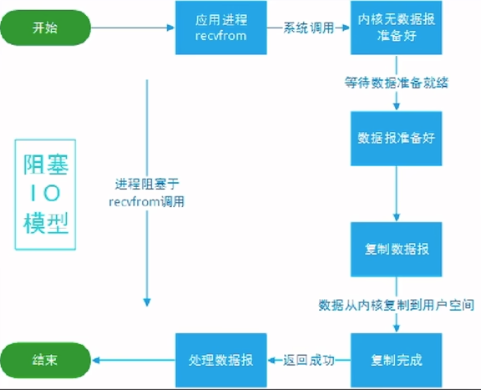
- 同步阻塞:老师去收作业,如果遇到一个学生没有写完,那么老师会等这个学生写完后才会收下一个学生的作业
- 异步阻塞:老师去收作业,遇到没有写完作业的学生,则跳过这个学生继续往后搜
- select/poll:学生做完作业会举手,但是老师不知道是谁做完了,需要轮询查询
- epoll:学生做完作业会举手,老师知道是谁做完了,直接去收作业
- 同步阻塞IO模型
- 同步非阻塞IO模型
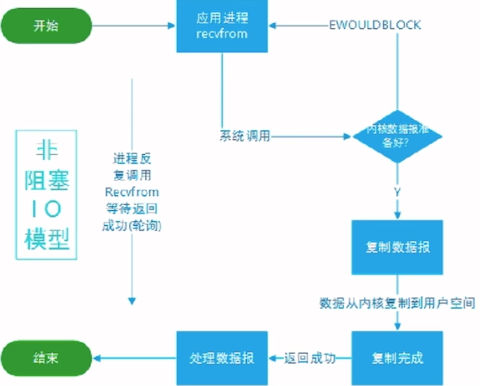
- 优点:单个socket阻塞,不会影响其他socket
- 缺点:需要不断的遍历进行系统调用,有一定的开销
- IO多路复用
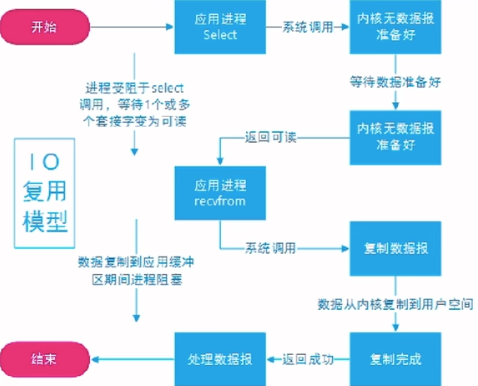
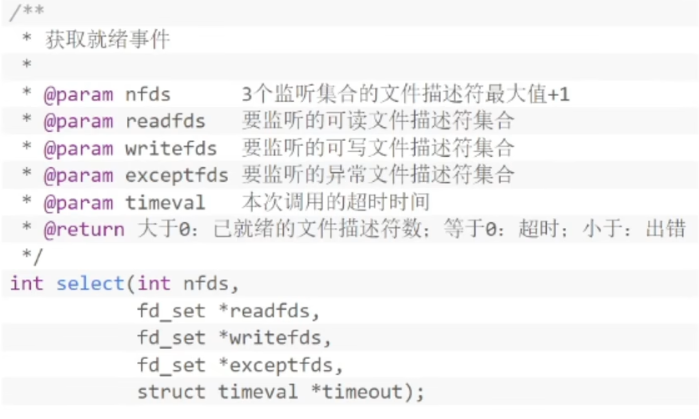
select:

- 将socket是否就绪检查逻辑下沉到操作系统层面,避免大量系统调用,告诉你有事件就绪,但是没有告诉你具体是哪个FD
- 优点:不需要每个FD都进行一次系统调用,解决了频繁的用户态内核态的切换问题
- 缺点:单线程的监听FD有限制(1024)。每次调用需要将FD从用户态拷贝到内核态(位图)。不知道具体是哪个FD就绪,需要遍历全部文件描述符。入参的3个fd_set集合每次调用都需要重置
poll
- 与select类似,但是优化了1024的限制,并对入参的数据做了优化
epoll

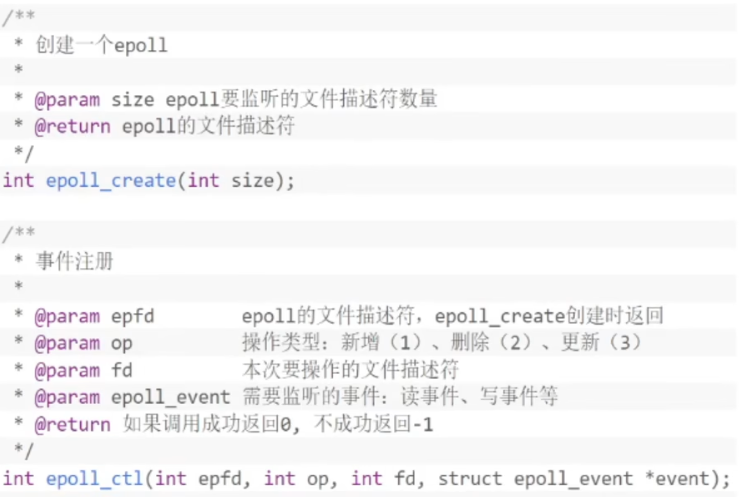

4. 存储数据结构
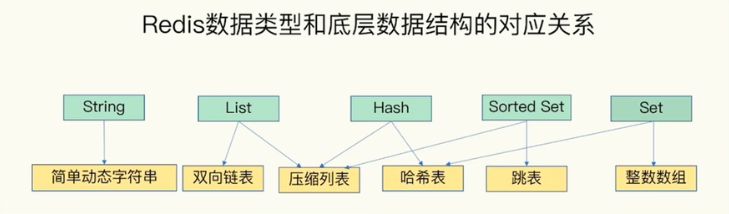
2.11 MySQL的主从复制,主主复制,集群模式的区别
1. 主从复制(Master-Slave Replication)
特点:
- 数据流向:数据从主服务器(Master)复制到一个或多个从服务器(Slave)。
- 读写分离:主服务器处理写操作和读操作,从服务器一般只处理读操作。
- 延迟:从服务器的数据可能会有一定的延迟,因为复制是异步或半同步的。
- 故障切换:如果主服务器故障,需要手动或使用工具进行故障切换。
优点:
- 简单易用,配置相对简单。
- 适用于读多写少的场景,通过增加从服务器来提升读取性能。
缺点:
- 写操作只能在主服务器上进行,写性能受限于主服务器的能力。
- 数据一致性可能存在延迟。
2. 主主复制(Master-Master Replication)
特点:
- 数据流向:两台或多台服务器互为主服务器,彼此之间进行数据同步。
- 读写分离:每个服务器既可以处理写操作也可以处理读操作。
- 冲突处理:需要解决数据冲突问题,通常通过应用层或特定的策略来处理。
优点:
- 提供高可用性和负载均衡,任意一台服务器都可以处理读写操作。
- 适用于需要高可用性和多点写入的场景。
缺点:
- 配置和管理相对复杂,特别是冲突处理。
- 数据一致性和冲突解决可能需要额外的逻辑和工具支持。
3. 集群模式(MySQL Cluster)
特点:
- 架构:使用 NDB Cluster 存储引擎,数据分布在多个节点上。
- 高可用性:提供自动故障切换和数据冗余,节点故障时数据仍然可用。
- 数据分布:数据分布在多个数据节点上,支持水平扩展。
- 实时性:提供低延迟的读写操作,适用于高性能需求的场景。
优点:
- 高可用性和高性能,适用于对可用性和性能要求高的应用。
- 自动故障切换和数据冗余,减少人工干预。
缺点:
- 配置和管理复杂,需要专业知识和经验。
- 适用于特定场景,不适合所有应用。
总结
- 主从复制:适用于读多写少的场景,配置简单,但写性能受限于主服务器。
- 主主复制:适用于需要高可用性和多点写入的场景,但需要解决数据冲突问题。
- 集群模式:适用于高可用性和高性能需求的场景,配置和管理复杂,但提供自动故障切换和数据冗余。
3. 设计模式
3.1. 单例模式
- 控制资源的使用:例如,数据库连接池、日志系统等,这些资源通常是重量级的,创建多个实例会导致资源浪费。
- 全局状态管理:在某些情况下,需要在整个应用程序中共享状态或配置,单例模式可以确保所有模块访问同一个实例。
- 跨模块通信:单例模式可以在不同模块之间传递信息,而不需要显式地传递对象。
1 | class Singleton: |
单例模式如何保证线程安全
在多线程环境下,单例模式需要确保只有一个线程能够创建实例,其他线程只能访问已经创建的实例。否则,可能会出现多个线程同时创建多个实例的情况,破坏单例模式的初衷。
下面是几种保证单例模式线程安全的方法:
方法一:使用线程锁
1 | import threading |
在这个实现中,我们使用了Python的threading.Lock来确保在多线程环境下的线程安全。只有在没有实例时,才会获取锁并创建实例。双重检查锁定(Double-Checked Locking)确保了即使在锁释放后也不会再次创建实例。
方法二:使用__init__方法中的锁
1 | import threading |
方法三:使用threading.RLock(递归锁)
1 | import threading |
RLock(递归锁)允许同一个线程多次获得同一个锁,适用于更复杂的场景。
方法四:使用threading.local(线程本地存储)
1 | import threading |
threading.local提供了线程本地存储,每个线程都有自己的独立实例,这种方式适用于需要每个线程有独立单例的情况。
以上方法都可以确保单例模式在多线程环境下的线程安全。选择哪种方法可以根据具体需求和应用场景来决定。
4. 系统设计
5. 计算机网络相关
5.1 HTTPS和HTTP的区别
- 安全性:HTTPS比HTTP更安全,因为数据都经过了TLS/SSL加密传输,HTTP是明文传输
- 速度;HTTP速度比较快,HTTPS还需要加解密过程
- 端口:HTTP是80端口,HTTPS是443端口
- 证书:HTTPS需要CA证书
5.2 HTTPS连接建立的过程
- 客户端发起连接请求
- 服务端发送证书给客户端,客户端验证证书的有效性(域名,过期时间等)
- 客户端将一个对称加密的密钥通过服务端的公钥加密,发送给服务端
- 服务端用自己的私钥解密出密钥
- 客户端和服务端用对称加密后的数据进行传输数据
5.3 DNS是什么?用了什么协议?
- DNS(Domain Name System),使用UDP协议,但是当传输的数据很大的时候,会使用TCP协议
5.4 DNS解析过程
- 用户访问url后开始DNS解析
- 查询本地缓存,包括HOST
- 查询本地DNS服务器
- 本地DNS服务器先查询缓存
- 查询根DNS服务器,返回顶级域名的DNS服务器
- 顶级域名DNS服务器查询到权威DNS服务器
- 权威DNS服务器返回IP地址
5.4 TCP和UDP的区别
- TCP协议是可靠的,因为连接的建立和断开都是双方确认过的。
- UDP协议是不可靠的,传输数据快
5.5 TCP和UDP在应用层有什么协议
- TCP: HTTP,HTTPS;FTP(文件传输);IMAP/POP3(邮件);SMTP(发送邮件);SSH等
- UDP:DNS;RTP(实时传输协议);DHCP(动态主机配置)
- ES为什么快?
- SSO登录的过程?下游系统怎么知道用户信息的?
- HTTP的Header中有哪些字段,控制cache的有哪些?
- session和cookie的区别?服务端session存储在哪里?
- 了解过微服务吗?
- 微服务有哪些优缺点?展开说说?
- MySQL主键用的什么?有什么优缺点?
- UUID用主键有什么优缺点?
- UUID怎么生成的?为什么不会重复?
- 什么类型的数据不适合做索引?
- 分库分表的经验?用什么工具?
- Title: 面试准备之八股文
- Author: LightedCode
- Created at : 2024-08-06 10:07:42
- Updated at : 2024-10-14 09:58:52
- Link: https://lightedcode.github.io/2024/08/06/面试准备之八股文/
- License: This work is licensed under CC BY-NC-SA 4.0.