
Interview Questions on MySQL Database

MySQL的事务(Transaction)
- 事务是数据库并发控制的基本单位
- 事务可以看作是一系列SQL语句的集合
- 事务必须全部执行成功,或者全部执行失败
事务的四个基本特性ACID
- 原子性(Atomicity):一个事务中所有的操作全部完成或失败
- 一致性(Consistency):事务开始和结束之后的数据完整性没有被破坏
- 隔离性(Isolation):允许多个事务同时对数据库进行修改和读写
- 持久性(Durability):事务结束之后,修改是永久的不会丢失
事务并发控制
- 如果不进行并发控制,可能会产生的现象
- 幻读(Phantom Read):一个事务第二次查出现了第一次没有的结果
- 非重复读(Nonrepeatable Read):一个事务重复读两次得到不同的结果
- 脏读(Dirty Read):一个输入读取到另一个事务没有提交的修改
- 修改丢失(Lost Update):并发写入造成其中一些修改丢失
事务的隔离级别
- 读未提交(Read Uncommitted):别的事务可以读取到未提交的改变
- 读已提交(Read Committed):只能读取已提交的数据
- 可重复读(Repeatable Read):同一个事务先后查询结果一样
- 串行化(Serializable):事务完全串行化执行,隔离级别最高,执行效率最低
高并发场景下的插入重复
- 使用数据库唯一索引
- 使用队列异步写入
- 使用redis等实现分布式锁
乐观锁,悲观锁
- 悲观锁是先获取所再进行操作。一锁二查三更新(select for update)
- 乐观锁先修改,更新的时候发现数据变了就回滚(check and set)一般通过版本号或者时间戳来实现
- 根据响应速度,冲突频率,重试代价来判断使用哪一种锁
MySQL常用的字段、含义和区别
- 字符串(文本)
- 数值
- 日期和时间
常用MySQL引擎的区别(InnoDB vs MyISAM)
- MyISAM不支持事务,InnoDB支持事务
- MyISAM不支持外键,InnoDB支持外键
- MyISAM只支持表锁,InnoDB支持行锁和表锁
- MyISAM支持全文索引,InnoDB不支持全文索引
MySQL索引原理和优化
原理、类型、结构
索引的基本概念
- 索引是数据表中一个或者多个列进行排序的数据结构,用于快速查找特定记录。
- 优点:索引能够大幅提升检索速度,尤其在大数据量的表中。
- 缺点:创建和维护索引会消耗额外的空间和时间,且在进行数据插入、删除和更新操作时,索引也需要同步更新。
索引的类型
主键索引(Primary Key Index):
- 唯一标识表中的每一行记录。
- 自动创建聚簇索引(Clustered Index)。
唯一索引(Unique Index):
- 保证列中的所有值都是唯一的。
- 可以有多个唯一索引。
普通索引(Index):
- 用于加速数据的访问,没有唯一性限制。
全文索引(Full-Text Index):
- 用于全文搜索,主要用于查找文本数据中的关键词。
组合索引(Composite Index):
- 在多个列上创建的索引,用于多列组合查询的优化。
索引的数据结构
查找结构的进化史
- 线性查找:逐个检查,简单但效率低。
- 二分查找:要求数据有序,效率高但插入操作慢。
- 哈希表:查询速度快,但占用空间大,不适合范围查询。
- 二叉查找树(BST):插入和查询速度快,但可能退化为链表。
- 平衡二叉树(如 AVL 树、红黑树):解决了 BST 退化问题,但仍可能在大数据量下深度较大。
- 多路查找树(如 B-Tree):每个节点有多个子节点,树的高度较低。
- 多路平衡查找树(如 B+ Tree):在 B-Tree 基础上优化,叶子节点通过链表相连,适合数据库索引。
B-Tree
B-Tree 是一种自平衡的多路搜索树,广泛用于数据库和文件系统中。其特点包括:
- 多路查找:每个节点可以有多个子节点,减少树的高度,从而减少查找路径的长度。
- 平衡性:所有叶子节点在同一层,保证了查找的时间复杂度为 (O(\log n))。
B+ Tree
MySQL 实际使用的是 B+ Tree 作为索引的数据结构,其特点包括:
- 叶子节点:只有叶子节点存储实际的数据记录指针,内部节点只存储键值。
- 链表结构:所有叶子节点通过链表相连,便于范围查询。
- 更高的扇出:由于内部节点不存储数据,可以有更多的子节点,树的高度更低,查询效率更高。
索引的优化
创建索引的原则
- 选择性高的列:选择性高的列(即不同值较多的列)能更有效地利用索引。
- 频繁作为查询条件的列:对经常出现在 WHERE 子句中的列创建索引。
- 避免对小表创建过多索引:小表中的数据量少,索引的作用有限,反而可能增加维护开销。
- 根据查询的需求来创建索引
- 经常用作查询条件的字段(WHERE)
- 经常用作表链接的字段
- 经常出现在order by,group by之后的字段
- 非空字段NOT NULL:MySQL很难对控制做查询优化
- 区分度高,离散度大,作为索引的字段只尽量不要有大量相同值
- 索引的长度不要太长(比较耗费时间)
索引的失效
- 模糊匹配:以%开头的LIKE语句,模糊搜索
- 类型隐转:出现隐式的类型转换:传入的参数类型和数据库表的类型不一致
- 最左匹配:没有满足最左前缀原则
聚集索引和非聚集索引
- 聚集索引:B+Tree的叶节点存储数据
- 非聚集索引:B+Tree的叶节点存储指针
索引的维护
- 定期重建索引:对于频繁更新的表,定期重建索引可以保持索引的效率。
- 监控索引使用情况:使用 MySQL 提供的工具(如
EXPLAIN)查看查询计划,了解索引的使用情况和效率。 - 删除不必要的索引:定期检查和删除不再使用或效果不佳的索引,减少维护开销。
索引的使用技巧
- 前缀索引:对于长字符串列,可以只索引前几个字符,以节省空间和提高查询速度。
- 覆盖索引:查询的字段被索引覆盖,可以避免回表操作,提高查询效率。
- 索引合并:MySQL 可以在某些情况下合并多个单列索引,提高查询效率。
索引的缺点和注意事项
- 空间开销:索引需要额外的存储空间,尤其是对于大表。
- 性能开销:索引的创建和维护会增加插入、更新和删除操作的时间。
- 选择合适的列:不恰当的索引可能导致性能下降,要慎重选择索引列。
MySQL的查询语句
- 表 A
| id | val |
|---|---|
| 1 | ab |
| 2 | a |
- 表 B
| id | val |
|---|---|
| 1 | ab |
| 3 | b |
内连接(INNER JOIN)
- 两张表都存在匹配时,才会返回匹配行
- 类似求两个表的交集
1 | select a.id as a_id, b.id as b_id, a.val as a_val, b.val as b_val from A inner join B on A.id = B.id |
查询结果
| a_id | b_id | a_val | b_val |
|---|---|---|---|
| 1 | 1 | ab | ab |
外连接(LEFT/RIGHT JOIN):返回一个表的行,即使另一个没有匹配
LEFT JOIN返回左表中所有记录,即使右表中没有匹配的记录
1 | select a.id as a_id, b.id as b_id, a.val as a_val, b.val as b_val from A left join B on A.id = B.id |
| a_id | b_id | a_val | b_val |
|---|---|---|---|
| 1 | 1 | ab | ab |
| 2 | Null | a | Null |
RIGHT JOIN返回右表中所有记录,即使左表中没有匹配的记录
1 | select a.id as a_id, b.id as b_id, a.val as a_val, b.val as b_val from A right join B on A.id = B.id |
| a_id | b_id | a_val | b_val |
|---|---|---|---|
| 1 | 1 | ab | ab |
| Null | 3 | Null | b |
全连接(FULL JOIN):只要某一个表存在匹配就返回
1 | select a.id as a_id, b.id as b_id, a.val as a_val, b.val as b_val from A full join B on A.id = B.id |
| a_id | b_id | a_val | b_val |
|---|---|---|---|
| 1 | 1 | ab | ab |
| 2 | NULL | a | NULL |
| NULL | 3 | NULL | b |
HAVING子句
在 SQL 中,HAVING 子句用于过滤分组后的结果。HAVING 子句通常与聚合函数一起使用,例如 COUNT、SUM、AVG 等,以过滤出符合条件的分组。
为了更好地理解 HAVING 子句的用法,假设我们有一张学生成绩表 student_scores,并且我们想找出至少有两门课程分数超过 80 分的学生。那么可以这样写:
1 | SELECT |
这个查询的逻辑是:
WHERE score > 80过滤掉所有分数不超过 80 分的记录。GROUP BY student_name将剩余的记录按学生名字分组。HAVING COUNT(*) >= 2只保留那些至少有两门课程分数超过 80 分的学生。
1 | SELECT |
SELECT student_name:- 选择学生的名字。
FROM student_scores:- 从
student_scores表中选择数据。
- 从
GROUP BY student_name:- 按学生名字分组,这意味着每个学生将成为一个分组。
HAVING MIN(score) > 80:HAVING子句用于过滤分组后的结果。MIN(score)计算每个学生所有课程中的最低分数。MIN(score) > 80这个条件确保每个学生的所有课程中最低分数都超过 80 分。
Redis
为什么要使用缓存?使用场景
- 缓解关系数据库的并发访问的压力:热点数据
- 减少响应时间:内存IO速度比磁盘快
- 提升吞吐量:Redis等内存数据库单机就可以支持很大并发
Redis常用的数据类型,使用方式
数据类型
- String字符串:实现简单的kv简直对存储,计数器
- List链表:双向链表:用户的关注,粉丝列表
- Hash哈希表:用来存储彼此相关信息的键值对
- Set(集合):存储不重复元素,比如用户的关注者
- Sorted Set(有序集合):实时信息排行榜
实现方式
- String:整数或者sds(Simple Dynamic String)
- List:ziplist或者double linked list
- Hash:ziplist或者hashtable
- Set: intset 或者hashtable
- Sorted Set:skiplist跳表
h
Skiplist跳表
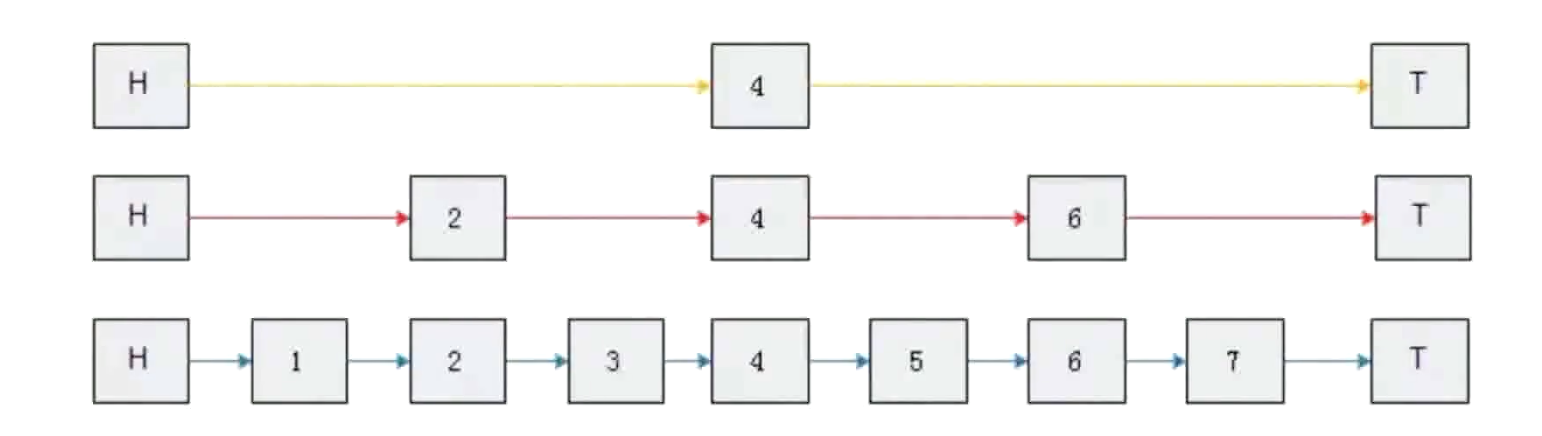
数据持久化方式
- 快照方式:把指定时间间隔把数据快照放在磁盘二进制文件中:dump.rdb
- AOF(Append Only File):每一个写命令追加到appendonly.aof中
Redis事务
- 讲多个请求打包,一次性,按需执行多个命令的机制
- Redis通过MULTI,EXEC,WATCH等命令实现事务的功能
Redis分布式锁
- setnx实现加锁操作,可以同时通过expire添加超时时间
- 锁的value可以通过使用一个随机的uuid或者特定的命名
- 释放所的时候通过uuid判断是否是该锁,是的话就执行delete释放锁
缓存使用模式:数据一致性问题
- Cache Aside:同时更新缓存和数据库
- Read/Write Through:先更新缓存,缓存负责同步更新数据库
- Write Behing Cache:先更新缓存,缓存定期异步更新数据库
缓存穿透问题
- 由于大量缓存查询不到的数据请求落到后端数据库,数据库压力增大
- 数据库也没有要查的数据
- 解决:对于没查到返回为None的数据也缓存
- 插入数据的时候删除相应缓存
缓存击穿问题
- 某些热点数据key过期,大量请求打到后端数据库
- 热点数据key失效导致数据库压力增大
- 分布式锁:获取锁的线程从数据库拉去数据更新缓存,其他线程等待
- 异步后台更新:后台任务针对过期的key自动刷新
缓存雪崩问题
- 缓存不可用或者大量缓存key同时失效,大量请求直接打到数据库
- 设置多级缓存:不同级别的key设置不同的超时时间
- 随机超时:key的超时时间随机设置防止同时超时
- 架构层面:提升系统可用性。
常考题
为什么MySQL数据库的主键使用自增的整数比较好
唯一性:自增整数确保每一行都有一个唯一的标识符,这对于主键的要求至关重要。
简单性:自增整数的实现和使用非常简单,不需要开发者手动生成唯一的标识符。
性能优化:
- 索引性能:整数类型的数据在索引和比较时比字符串类型的数据更快。因为整数占用的存储空间较小,能更高效地进行排序和查找。
- 插入性能:自增整数主键的插入操作通常是顺序的,这有助于减少B树索引的分裂和重组,提升插入性能。
存储效率:整数类型的数据占用的存储空间较小(例如,INT类型占用4字节,BIGINT类型占用8字节),相比于字符串或UUID等其他类型的主键,能够节省存储空间。
可读性:自增整数主键通常更容易阅读和理解,尤其是用于调试和日志记录时。
方便引用:自增整数主键在作为外键引用时也更加方便,能够简化外键关系的管理和维护。
避免冲突:在分布式系统或多客户端同时插入数据时,自增整数主键能够依赖数据库自身的机制来避免冲突,而不需要额外的逻辑来保证唯一性。
尽管自增整数主键有许多优点,但在某些情况下,其他类型的主键(例如UUID)可能更适合,特别是在需要全球唯一标识符或需要避免顺序暴露的情况下。选择主键类型时应根据具体的应用场景和需求进行权衡。
使用UUID可以吗?为什么?
优点
全局唯一性:UUID可以在分布式系统中生成,并且具有全局唯一性,不需要依赖数据库的自增机制。这在多服务器环境中非常有用。
安全性:UUID的随机性使得它们难以预测,相比自增整数主键更难通过观察主键值推测插入顺序或数据量。
避免主键冲突:在多数据库实例或多客户端同时插入数据的场景中,使用UUID可以有效避免主键冲突,而不需要协调生成主键的机制。
缺点
存储空间:UUID占用的存储空间较大(通常为16字节),相比于常见的整数主键(如4字节的INT),会增加存储开销。
索引性能:UUID的随机性导致插入数据时索引树会频繁分裂和重组,影响插入性能和索引效率。相比之下,自增整数主键的顺序插入更有利于索引的维护。
查询性能:由于UUID的长度和复杂性,查询操作的性能可能会受到影响,特别是在涉及大量数据时。
可读性:UUID不如自增整数主键易读和易记,对于调试和日志记录来说,UUID的使用可能会增加复杂性。
使用UUID的建议
如果决定使用UUID作为主键,可以考虑以下优化措施:
UUID格式优化:可以使用UUID的版本1或版本2,这些版本包含时间戳信息,可以部分缓解索引分裂的问题。
使用BINARY类型:在MySQL中,可以将UUID存储为BINARY(16)类型,而不是CHAR(36),这样可以节省存储空间并提高查询性能。
分段存储:一些系统会将UUID分解为多个部分存储,或者对UUID进行排序(如将时间戳部分放在前面),以改善索引性能。
结论
是否使用UUID作为主键应根据具体的应用场景和需求进行权衡。如果需要全局唯一性和分布式系统的支持,UUID是一个不错的选择。但需要注意其对存储和性能的影响,并采取相应的优化措施。如果主要关注性能和存储效率,自增整数主键可能是更合适的选择。
基于Redis编写代码实现一个简单的分布式锁(支持超时时间参数)
1 | import redis |
如果redis单个节点宕机了,如何处理?
- 哨兵模式
- 集群模式
- 客户端重试
还有其他分布式锁的实现方案吗?
1. Zookeeper
Zookeeper 是一个分布式协调服务,常用于实现分布式锁。它通过创建临时节点来实现锁的获取和释放。
示例代码
1 | from kazoo.client import KazooClient |
2. Etcd
Etcd 是一个分布式键值存储,通常用于服务发现和配置共享。它也可以用于实现分布式锁。
示例代码
1 | from etcd3 import Etcd3Client |
3. Consul
Consul 是一个分布式服务发现和配置管理工具,也可以用于实现分布式锁。
示例代码
1 | import consul |
4. Redlock
Redlock 是一种基于Redis的分布式锁算法,旨在解决单个Redis实例的单点故障问题。它通过在多个独立的Redis实例之间协调来实现高可用性。
示例代码
1 | import redis |
- Title: Interview Questions on MySQL Database
- Author: LightedCode
- Created at : 2024-08-04 22:12:36
- Updated at : 2024-10-14 09:58:52
- Link: https://lightedcode.github.io/2024/08/04/Interview-Questions-on-MySQL-Database/
- License: This work is licensed under CC BY-NC-SA 4.0.