
Interview Questions on Network Protocols and Web Frameworks

浏览器输入一个url中间经历的过程
- 中间涉及到了哪些过程
- 包含哪些网络协议
- 每个协议都干了什么
URL 解析
- 浏览器解析用户输入的 URL,拆分出协议、主机名、端口、路径、查询参数等部分。
检查浏览器缓存
- 浏览器首先检查本地缓存是否有对应的资源,如果有且未过期,直接返回缓存内容。
DNS 解析
- DNS 缓存检查:浏览器检查本地 DNS 缓存、操作系统缓存、路由器缓存等。
- Host 文件检查:操作系统检查本地的 Hosts 文件。
- DNS 查询:如果缓存中没有找到,浏览器向 DNS 服务器发起查询请求,得到目标服务器的 IP 地址。
建立 TCP 连接
- TCP 三次握手:浏览器与服务器之间通过三次握手建立 TCP 连接。
发送 HTTP 请求
- 浏览器构建 HTTP 请求报文,并通过建立的 TCP 连接发送给服务器。
服务器处理请求
- 反向代理服务器(如 Nginx):接收请求并根据配置决定如何处理(如负载均衡、静态资源处理等)。
- 应用服务器(如 WSGI 服务器):将请求转发给应用程序(如 Flask、Django)。
- Web 框架:应用程序处理请求,可能涉及数据库查询、业务逻辑处理等,生成响应。
服务器返回响应
- 应用服务器将生成的响应通过反向代理服务器返回给浏览器。
浏览器渲染页面
- 解析 HTML:浏览器解析 HTML 文档,生成 DOM 树。
- 解析 CSS:构建 CSSOM 树。
- 解析 JavaScript:执行脚本,可能会修改 DOM 树和 CSSOM 树。
- 合成页面:将 DOM 树和 CSSOM 树合成渲染树,绘制页面。
TCP 连接关闭
- TCP 四次挥手:浏览器和服务器之间通过四次挥手关闭 TCP 连接。
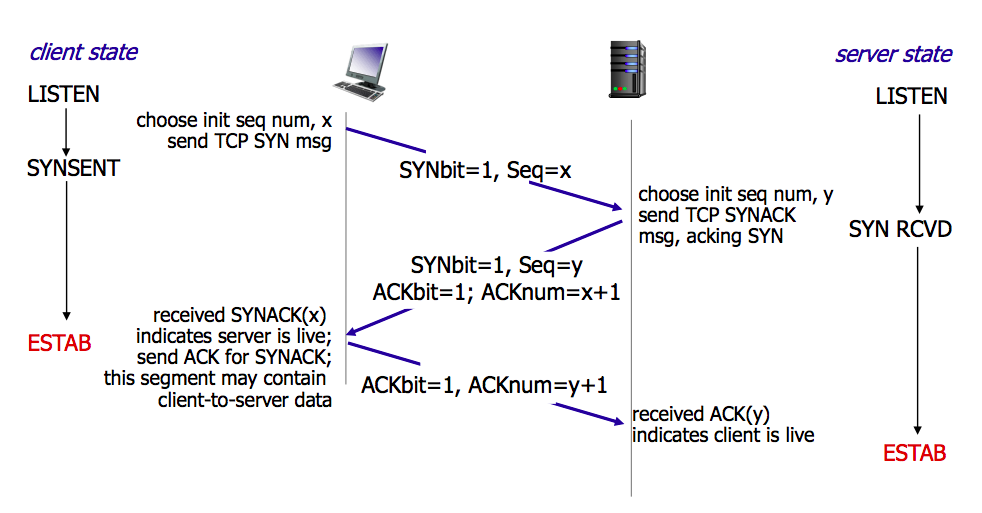
TCP三次握手
三次握手的设计是为了确保双方都能够可靠地知道对方的存在,并且双方的发送和接收能力都是正常的。
- 客户端发送SYN报文,表示想要建立链接,包含SN序列号
- 服务端收到后,想客户端发送SYN-ACK确认报文,表示我收到你的请求了,并包含SN序列号
- 客户端收到确认报文后,向服务端发送ACK确认报文,表示收到服务器的确认报文,此时链接建立
为什么不是二次握手或者四次握手
- 两次握手的问题:
- 如果采用两次握手,可能会导致“已失效的连接请求报文段”被服务器误认为是一个新的连接请求。例如,客户端发送第一个 SYN 报文后,由于网络问题该报文长时间滞留在网络中,客户端没有收到服务器的 SYN-ACK 报文,认为连接失败,于是再次发送 SYN 报文并成功建立连接。此时,旧的 SYN 报文到达服务器,服务器会误以为客户端又发起了一个新的连接,从而同意连接并发送 SYN-ACK 报文。这样服务器就会建立一个无用的连接,浪费资源。
- 四次握手的冗余:
- 四次握手并不是必要的,因为三次握手已经可以确保双方都能正常发送和接收数据。增加一次握手并不会带来更多的确认信息,反而会增加连接建立的时间和复杂性。
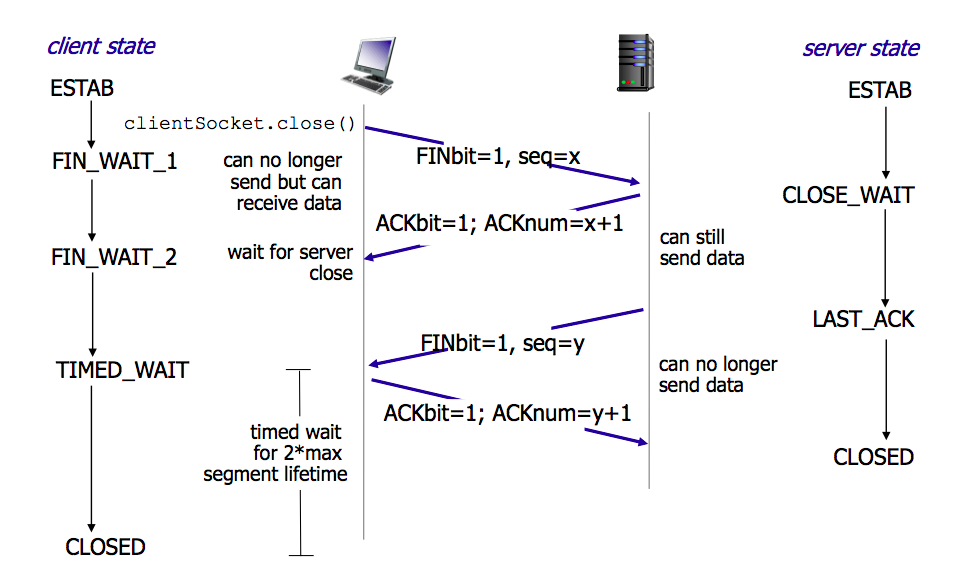
TCP四次挥手
四次挥手的设计是为了确保双方都能可靠地结束数据传输,并且双方都确认对方已经关闭连接。
- 客户端向服务端发送FIN(结束)报文,表示客户端没有数据要发送了,但是可以接收数据
- 服务端收到FIN报文后,向客户端发送一个ACK确认报文,此时服务端进入关闭等待状态,但仍然可以发送数据给客户端
- 服务端向客户端发送FIN报文,表示服务端也没有数据要发送了
- 客户端收到FIN报文后,向服务端发送一个ACK确认报文,表示收到了服务端的结束报文。此时客户端进入时间等待状态,确保服务器能收到这个ACK报文,之后姐可以关闭链接
为什么需要四次挥手
全双工通信的关闭:
- TCP 连接是全双工的,即双方都可以同时发送和接收数据。因此,关闭连接需要确保双方的数据传输都已经结束。
- 第一次挥手:客户端发送 FIN,表示客户端的数据发送已经结束。
- 第二次挥手:服务器收到 FIN 后发送 ACK,确认客户端的数据发送已经结束。
- 第三次挥手:服务器发送 FIN,表示服务器的数据发送也已经结束。
- 第四次挥手:客户端收到 FIN 后发送 ACK,确认服务器的数据发送也已经结束。
防止数据丢失:
- 四次挥手确保双方都有机会发送和接收最后的数据,避免数据丢失。
- 服务器在收到客户端的 FIN 后,可能还有未发送完的数据,因此需要发送 ACK 确认,并在数据发送完后再发送 FIN。
为什么不能三次挥手?
三次挥手的问题:
- 如果采用三次挥手,可能会导致数据丢失。例如,如果客户端发送 FIN 后,服务器立即发送 FIN 而不发送 ACK 确认客户端的 FIN,客户端可能会误以为服务器的数据发送已经结束,从而关闭连接,导致服务器未发送完的数据丢失。
四次挥手的必要性:
- 四次挥手确保了双方都能完全关闭连接,并且都确认对方已经关闭连接,避免数据丢失和连接异常。
TCP和UDP的区别
TCP(传输控制协议)和UDP(用户数据报协议)是两种常见的传输层协议,它们在数据传输方式和应用场景上有显著的区别。以下是它们的主要区别:
1. 连接方式
- TCP:面向连接的协议。在传输数据之前,需要先建立连接(三次握手),传输结束后需要断开连接(四次挥手)。
- UDP:无连接的协议。发送数据之前不需要建立连接,直接发送数据包。
2. 可靠性
- TCP:提供可靠的数据传输。通过确认机制、序列号、重传控制等手段确保数据的完整性和顺序性。
- UDP:不保证可靠性。数据包可能会丢失、重复或乱序,应用层需要自己处理这些问题。
3. 数据传输方式
- TCP:面向流的协议。数据作为一个连续的字节流进行传输,适合传输大数据量。
- UDP:面向报文的协议。数据以独立的报文形式进行传输,每个报文都是一个独立的单元。
4. 速度
- TCP:由于提供可靠性和流量控制,传输速度相对较慢。
- UDP:由于没有连接建立和确认机制,传输速度较快,适合对速度要求高的应用。
5. 应用场景
- TCP:适用于需要可靠传输的应用,如网页浏览(HTTP/HTTPS)、文件传输(FTP)、电子邮件(SMTP)。
- UDP:适用于对速度要求高且可以容忍部分数据丢失的应用,如视频直播、在线游戏、DNS查询。
6. 流量控制和拥塞控制
- TCP:具有流量控制和拥塞控制机制,能根据网络状况调整传输速率,避免网络拥堵。
- UDP:没有流量控制和拥塞控制机制,发送数据的速率不受网络状况影响。
总结来说,TCP适合需要可靠性和顺序性的应用,而UDP则适合需要高效、实时传输的应用。选择使用哪种协议,取决于具体的应用需求。
HTTP协议
HTTP的请求和响应
- HTTP请求的组成
- 状态行
- 请求头
- 消息主体
- HTTP响应的组成
- 状态行
- 响应头
- 响应正文
- HTTP常见状态码
- 1xx 信息:服务器收到请求,需要请求这继续执行操作
- 2xx 成功:操作被成功接受并处理
- 3xx 重定向::需要进一步操作
- 4xx 客户端错误:请求有语法错误或者无法完成请求
- 5xx 服务端错误:服务端在处理请求的过程中发生错误
HTTP的操作
- GET和POST的区别
- Restful语义:GET获取,POST创建
- GET请求是幂等的,POST非幂等
- GET请求参数放到URL明文中,长度有限制;POST参数在请求体,更安全
- 幂等方法
- 无论调用多少次都得到相同结果的HTTP方法
- 幂等的方法客户端可以安全的重发请求
- 安全方法
- 方法会不会修改数据
| HTTP 方法 | 幂等性 | 安全性 |
|---|---|---|
| GET | 是 | 是 |
| POST | 否 | 否 |
| PUT | 是 | 否 |
| DELETE | 是 | 否 |
| HEAD | 是 | 是 |
| OPTIONS | 是 | 是 |
| PATCH | 否 | 否 |
HTTP长链接
- 短链接:建立链接,数据传输,关闭链接(这样开销很大)
- 长链接:Connection: Keep-alive。保持TCP链接不断开
- 长链接下如何区分不懂的HTTP请求:Content-Length | Transfer-Encoding: chunked
cookie和session的区别
- session一般是服务器生成后给客户端(可以通过url或者cookie)
- cooike是实现session的一种机制,通过HTTP的cookie字段实现
- session通过在服务器里保存sessionid来识别用户,cookie保存在客户端
TCP/UDP socket编程
TCP编程原理
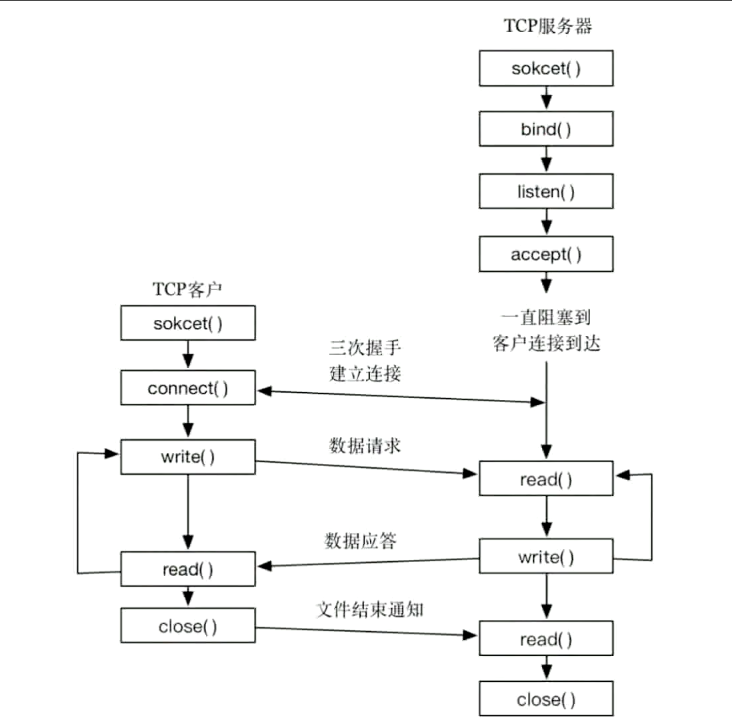
如何使用socket模块
如何建立TCP socket客户端和服务端
1 | import socket |
1 | import socket |
1 | # Server |
socket如何发送HTTP请求
1 | import socket |
1 | HTTP/1.1 200 OK |
Unix IO模型
- Blocking IO:阻塞式IO模型
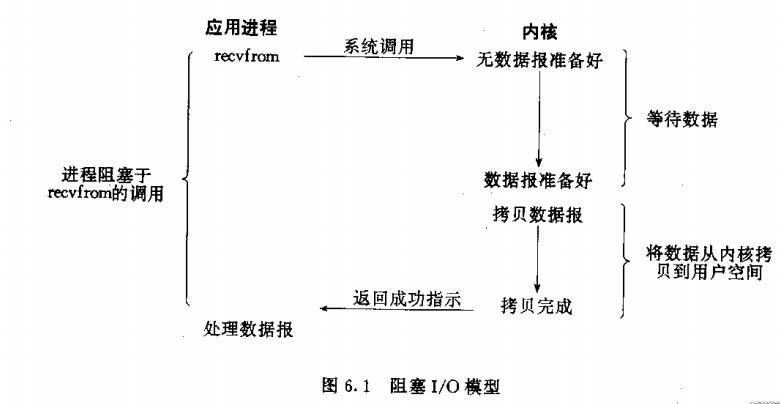
- Nonblocking IO:非阻塞式IO
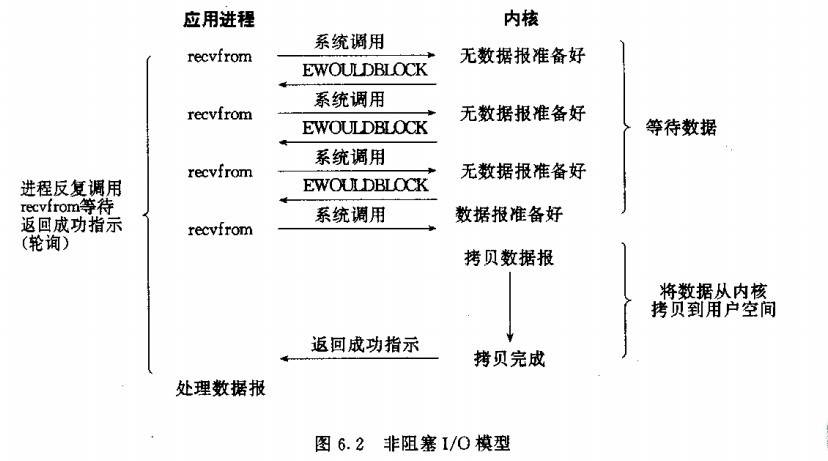
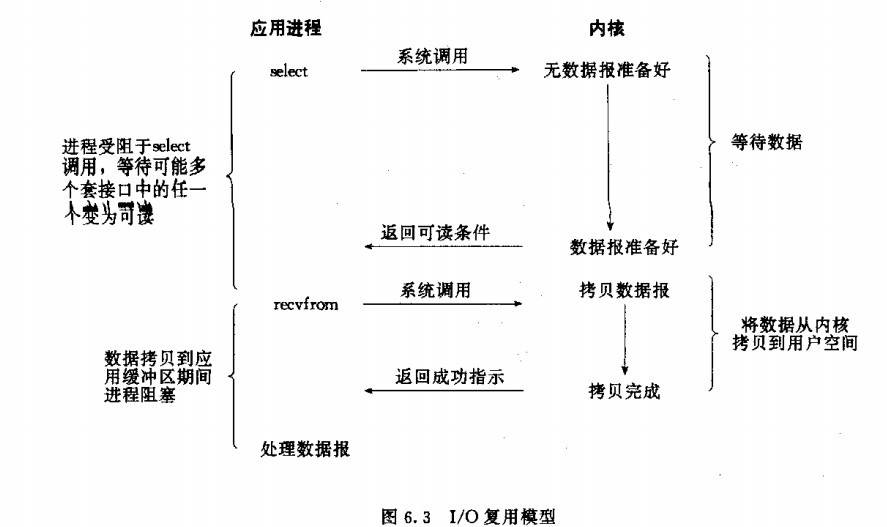
- IO multiplexing:IO复用
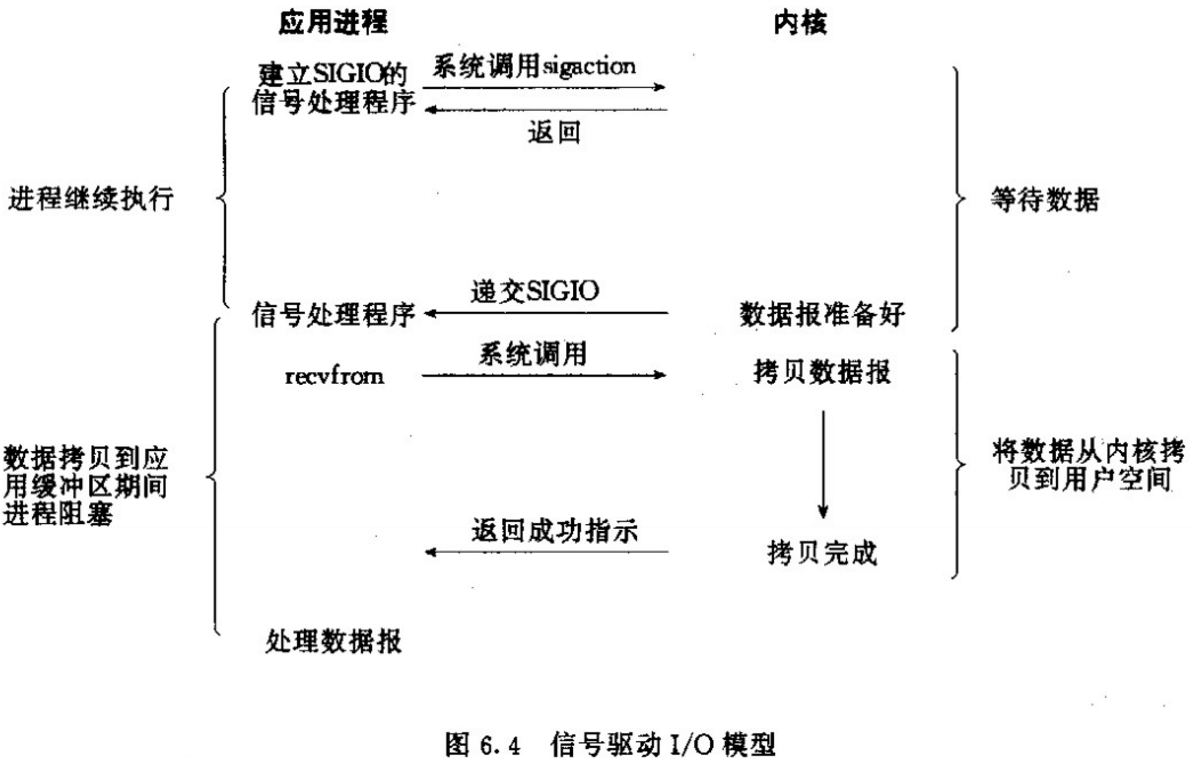
- Signal Driven IO:信号驱动IO
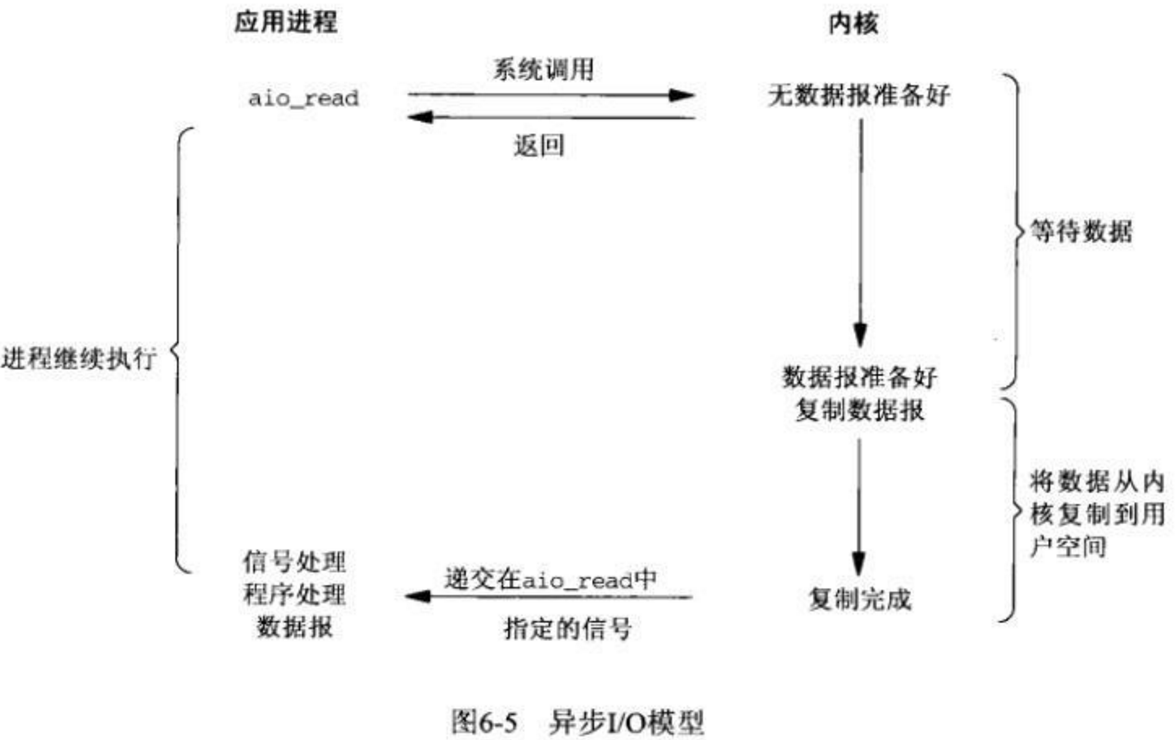
- asynchronous IO:异步IO
提升并发能力
- 多线程模型
- 多进程模型
- IO多路复用,实现单进程同时处理多个socket请求
IO多路复用
- 为了实现高并发需要一种机制并发处理,使用单线程/单进程处理多个socket
- Linux中常见的是 select/poll/epoll
- select
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。 - poll
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。 - epoll
epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就绪态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
- select
Python实现IO多路复用:selectors模块
1 | import selectors |
Python并发网络库
Tornado vs Gevent vs Asyncio
概述和背景
Tornado:
- Tornado最初是由FriendFeed开发,后来被Facebook收购。它不仅是一个并发网络库,也是一个web框架。
- 主要用于高性能的网络应用,适合处理大量的长连接(如WebSocket)。
Gevent:
- Gevent基于libev或libuv库,使用绿色线程(greenlet)实现并发。
- 通过猴子补丁(monkey patching)修改内置的socket等模块,使得标准库中的阻塞操作变为非阻塞。
Asyncio:
- Asyncio是Python 3.4引入的标准库,基于原生协程(coroutine)实现。
- 提供了事件循环、任务、未来对象等构建块,用于构建并发网络应用。
详细特点
Tornado:
- 非阻塞I/O和事件驱动。
- 内置HTTP服务器和Web框架支持。
- 强大的WebSocket支持。
- 缺点:相对较重,学习曲线较陡。
Gevent:
- 使用绿色线程实现并发,代码风格类似于同步编程。
- 通过猴子补丁使得标准库中的阻塞操作变为非阻塞。
- 缺点:某些情况下猴子补丁可能引入兼容性问题。
Asyncio:
- 基于原生协程,提供现代且强大的并发支持。
- 与Python标准库紧密集成。
- 缺点:需要理解事件循环和协程的概念,代码风格与传统同步编程不同。
性能比较
- Tornado在处理大量长连接时表现出色。
- Gevent在I/O密集型任务中表现良好,但在CPU密集型任务中可能需要配合多进程。
- Asyncio在处理高并发和复杂异步任务时表现优异。
生态系统和社区支持
Tornado:
- 有丰富的第三方扩展库和工具支持。
- 社区活跃,但相对较小。
Gevent:
- 有较多的第三方库支持,特别是在网络和I/O领域。
- 社区活跃,维护良好。
Asyncio:
- 作为标准库,拥有广泛的社区支持和大量的第三方库。
- 发展迅速,得到Python官方的持续改进和支持。
代码示例
Tornado:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, world")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()Gevent:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from gevent import monkey
monkey.patch_all()
from gevent.pywsgi import WSGIServer
from flask import Flask
app = Flask(__name__)
def hello():
return "Hello, world"
if __name__ == "__main__":
http_server = WSGIServer(('0.0.0.0', 5000), app)
http_server.serve_forever()Asyncio:
1
2
3
4
5
6
7
8
9
10
11import asyncio
from aiohttp import web
async def hello(request):
return web.Response(text="Hello, world")
app = web.Application()
app.add_routes([web.get('/', hello)])
if __name__ == "__main__":
web.run_app(app)
常见问题和解决方案
Tornado:
- 问题:如何处理阻塞操作?
- 解决方案:使用Tornado提供的异步I/O支持或将阻塞操作移到线程池。
- 问题:如何处理阻塞操作?
Gevent:
- 问题:猴子补丁引起的兼容性问题。
- 解决方案:尽量在程序入口处应用猴子补丁,并测试兼容性。
- 问题:猴子补丁引起的兼容性问题。
Asyncio:
- 问题:如何在协程中调用阻塞函数?
- 解决方案:使用
asyncio.to_thread将阻塞函数移到线程池中执行。
- 解决方案:使用
- 问题:如何在协程中调用阻塞函数?
1 |
|
说明:
初始化:
AsyncCrawler类接受两个参数:最大并发任务数max_concurrent_tasks和需要爬取的 URL 列表urls。results用于存储抓取结果。
异步抓取:
fetch_url方法是一个异步方法,用于抓取单个 URL 的内容。使用aiohttp库的ClientSession进行 HTTP 请求。process_response方法处理响应,将结果存储在results列表中。
运行爬虫:
run方法创建一个带有并发限制的TCPConnector,并创建一个ClientSession实例。- 使用
asyncio.gather并发执行所有抓取任务。
主程序:
- 在主程序中,创建
AsyncCrawler实例并运行run方法。 - 最后,打印每个抓取结果的前 100 个字符。
- 在主程序中,创建
注意事项:
- 这个异步爬虫类使用
aiohttp库来处理异步 HTTP 请求。 asyncio.run用于运行异步事件循环。- 异步方法
fetch_url使用await关键字等待异步操作的完成。 process_response方法在fetch_url方法中被调用,用于处理响应并将结果保存到results列表中。
- Title: Interview Questions on Network Protocols and Web Frameworks
- Author: LightedCode
- Created at : 2024-08-03 22:31:04
- Updated at : 2024-10-14 09:58:52
- Link: https://lightedcode.github.io/2024/08/03/Interview-Questions-on-Network-Protocols-and-Web-Frameworks/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments