
Linux Basics And Operating System Fundamentals

Linux命令
查询命令的用法
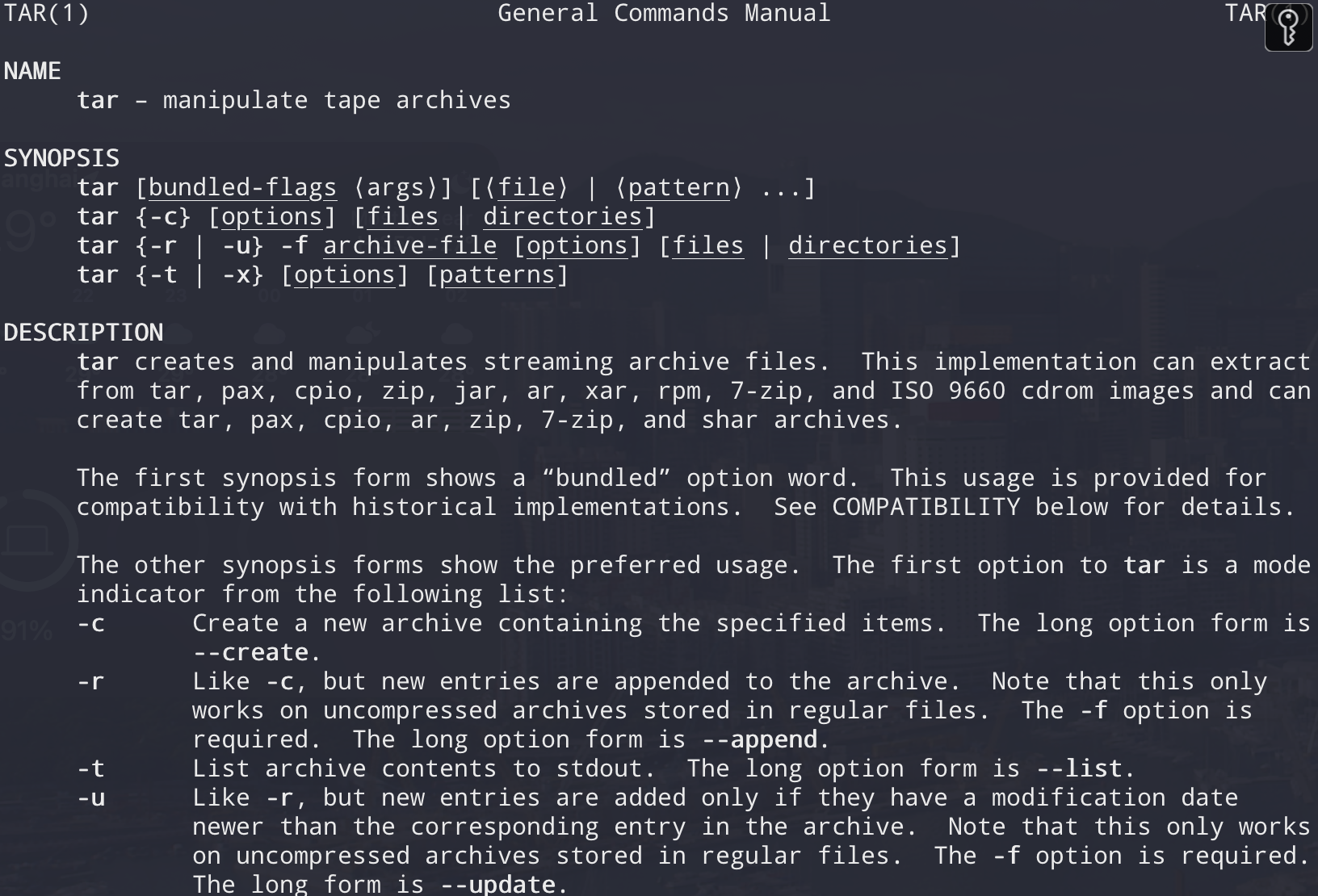
- man命令
1 | man tar |
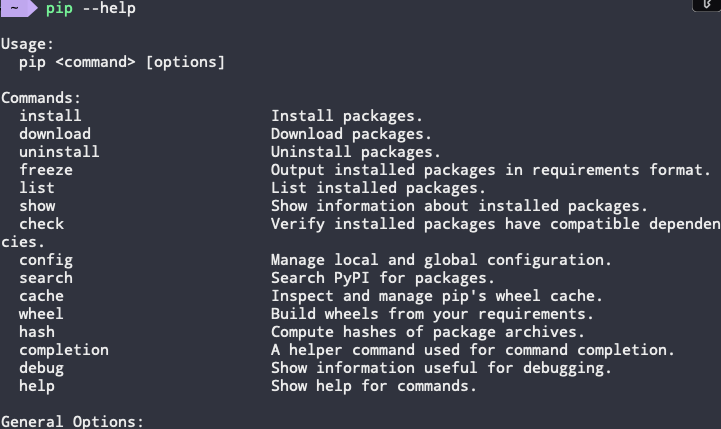
- –help参数
1 | pip --help |
- tldr
文件/目录操作命令
- chown/chmod/chgrp
- ls/rm/cd/cp/mv/touch/rename/ln(软链接和硬链接)
- locate/find/grep 定位查找和搜索
- 编辑器 vi/nano
- cat/head/tail 查看文件
- more/less 交互式查看文件
进程操作命令
- ps 查看进程
- kill 杀死进程
kill命令是 UNIX 和 Linux 系统中用来发送信号给进程的工具。尽管它的名字听起来像是专门用来终止进程的,但实际上它可以发送各种信号,这些信号可以用于不同的目的,比如暂停、继续或者终止进程。 - top/htop 监控进程
内存操作命令
- free 查看可用内存
free命令是 Linux 系统中用于显示内存使用情况的工具。它提供了系统中物理内存和交换内存的使用情况,包括总量、已用量、空闲量和缓冲/缓存的内存量。
free命令的作用
free 命令的主要作用是:
- 显示物理内存和交换内存的使用情况:包括总量、已用量、空闲量和缓冲/缓存的内存量。
- 监控系统内存使用情况:帮助系统管理员和用户了解当前系统的内存使用状态,从而进行相应的调整和优化。
free命令的基本语法
1 | free [options] |
常用参数
- **
-b**:以字节为单位显示内存使用情况。 - **
-k**:以千字节为单位显示内存使用情况。这是默认选项。 - **
-m**:以兆字节为单位显示内存使用情况。 - **
-g**:以千兆字节为单位显示内存使用情况。 - **
--tera**:以太字节为单位显示内存使用情况。 - **
-h**:以人类可读的格式显示内存使用情况(自动选择合适的单位,如 KB、MB、GB)。 - **
-s <interval>**:每隔<interval>秒重复显示内存使用情况。 - **
-t**:显示内存总量,包括物理内存和交换内存的总量。 - **
-c <count>**:指定显示的次数。
示例
- 显示内存使用情况(默认单位为 KB):
1 | free |
- 以人类可读的格式显示内存使用情况:
1 | free -h |
- 以兆字节为单位显示内存使用情况:
1 | free -m |
- 每隔 5 秒重复显示内存使用情况:
1 | free -s 5 |
- 显示内存总量,包括物理内存和交换内存的总量:
1 | free -t |
输出解释
free 命令的输出通常包含以下几列:
- total:总内存量。
- used:已用内存量。
- free:空闲内存量。
- shared:共享内存量(一般用于 tmpfs)。
- buff/cache:缓冲和缓存的内存量。
- available:可用内存量(这是估计值,表示应用程序可以使用的内存量,而不会影响系统性能)。
示例输出:
1 | total used free shared buff/cache available |
通过 free 命令,用户可以快速了解系统的内存使用情况,帮助进行系统性能监控和优化。
网络操作命令
ifconfig 查看网卡信息
lsof/netstat 查看端口信息
ssh/scp 远程登录/赋值
tcpdump抓包
用户/组操作命令
- useradd/usermod
- groupadd/groupmod
操作系统
进程和线程
- 进程是对运行时程序的封装,是系统资源调度和分配的基本单位。
- 线程是进程的子任务,是CPU调度和分配的基本单位,实现进程内并发。
- 一个进程可以包含多个线程,线程依赖进程存在,并共享进程的内存。
线程安全
- 线程安全问题:一个线程的修改可能被另一个线程的修改覆盖,导致数据不一致。
- Python中的线程安全机制还包括锁(Lock)、重入锁(RLock)、条件变量(Condition)等,可以用于更复杂的线程同步场景。
Python里哪些操作是线程安全的
- 原子操作:在Python中,一些内置操作是原子性的,如对简单数据类型的赋值操作、一些列表操作(如append)等。
线程同步
- 互斥量(锁):通过互斥机制防止多个线程同时访问公共资源。
- 信号量(Semaphore):控制同一时刻多个线程访问同一个资源的线程数。
- 事件(Event):通过通知的方式保持多个线程同步。
进程间通信的方式
- 管道(Pipe):匿名管道和有名管道(命名管道)。
- 信号(Signal):比如Ctrl + C产生SIGINT程序终止信号。
- 消息队列(Message Queue):用于在进程之间传递消息。
- 共享内存(Shared Memory):多个进程共享一块内存区域。
- 信号量(Semaphore):用于控制对共享资源的访问。
- 套接字(Socket):常用于网络通信。
Python的多线程
threading模块- 使用
threading.Thread来创建线程。 start()方法启动线程。- 可以用
join()等待线程结束。
- 使用
1 | import threading |
Python的多进程
Python有全局解释器锁(GIL),可以使用多进程实现CPU密集型程序
multiprocessing多进程模块- 使用
multiprocessing.Process实现多进程。 - 一般用于CPU密集型任务,避免GIL影响。
- 使用
1 | from multiprocessing import Process |
GIL对CPU密集型程序的影响
1. 线程无法并行执行
在有GIL的情况下,即使在多核处理器上运行多个线程,这些线程也无法真正并行执行。GIL会使得Python解释器在任何时刻只能执行一个线程的Python代码,这意味着多个线程在执行CPU密集型任务时,实际上是串行化的,而不是并行化的。
2. 性能瓶颈
对于CPU密集型任务(如复杂计算、数据处理等),每个线程都需要大量的CPU时间。由于GIL的存在,多个线程无法同时利用多个CPU核心,这导致了性能瓶颈。即使在多核处理器上,CPU利用率也不能达到预期的水平。
3. 上下文切换开销
在多线程程序中,GIL会频繁地在不同线程之间切换,导致大量的上下文切换。这些上下文切换不仅没有带来并行执行的好处,反而增加了额外的开销,进一步降低了程序的效率。
多线程与多进程的区别和应用场景
- 多线程适用于I/O密集型任务,如网络请求、文件读写等,因为这些任务在等待I/O操作时不会消耗CPU资源。
- 多进程适用于CPU密集型任务,如计算密集型任务,因为多进程可以绕过GIL限制,充分利用多核CPU。
内存管理机制
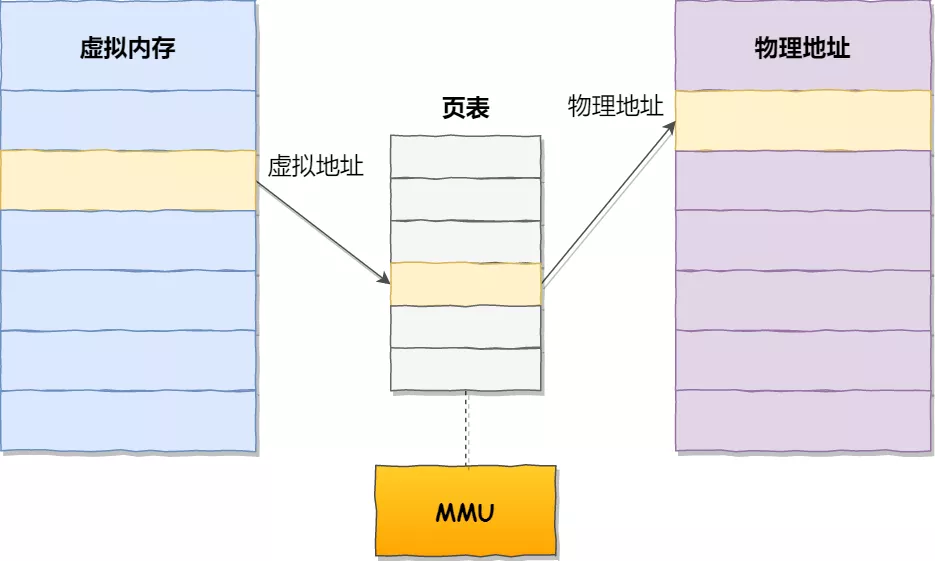
分页机制
- 逻辑地址和物理地址分离的内存分配管理方案
- 程序的逻辑地址分为固定大小的页(Page)
- 物理地址划分为同样大小的额帧(Frame)
- 通过一个页表对应逻辑地址和物理地址
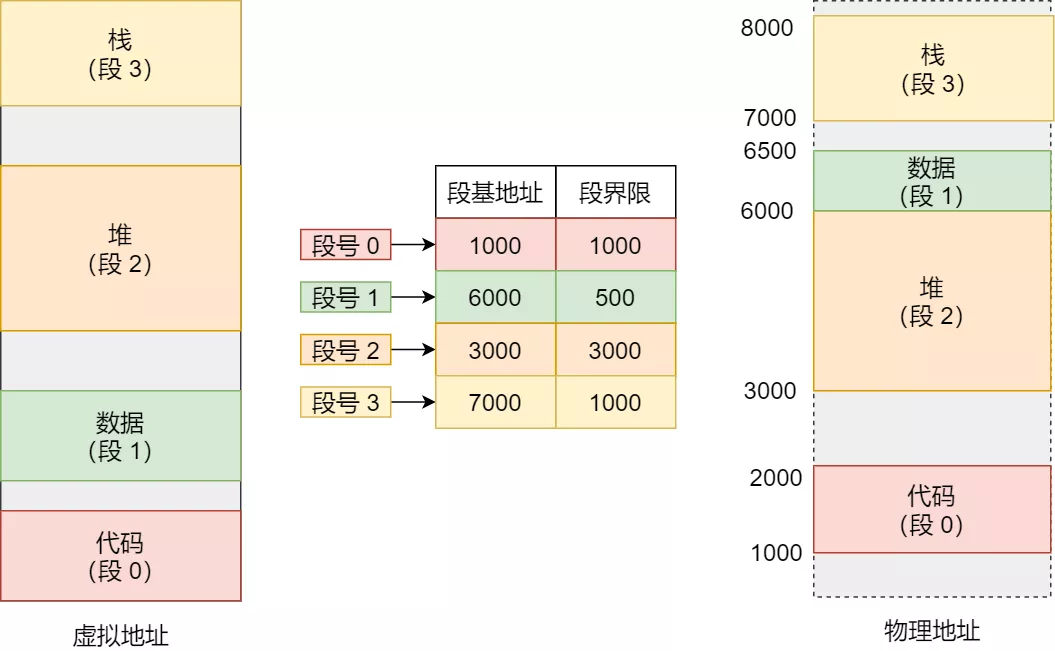
分段机制
- 分段是为了满足代码的一些逻辑需求。代码段、数据段、堆栈段。
- 数据共享,数据保护,动态链接等
- 通过段表实现逻辑地址和物理地址的映射关系
- 每个段内部是联系内存分配,段和段之间是离散分散的
- 分页:将内存划分为固定大小的页,主要解决内存碎片问题,简化管理,但需要页表和额外的硬件支持。
- 分段:将内存划分为不同大小的段,更符合程序逻辑结构,灵活性更高,但容易产生外部碎片,管理复杂。
虚拟内存
- 通过把一部分暂时不用的内存信息放到硬盘上
- 局部性原理(时间局部性和空间局部性),程序运行的时候只有部分必要的信息装入内存
- 系统似乎提供了比实际内存大得多的容量,成为虚拟内存
内存抖动(颠簸)
- 频繁的页调度,进程不断产生缺页终端
- 置换一个页,有不断再次需要这个页
- 运行程序太多;页面替换策略不好。终止进程或者增加物理内存
Python的垃圾回收机制(GC)原理
Python的垃圾回收机制主要通过引用计数和循环垃圾回收两个机制来管理内存。
1. 引用计数(Reference Counting)
引用计数是Python内存管理的基础机制。每个对象都有一个引用计数器,用于记录有多少个引用指向该对象。当一个对象的引用计数变为零时,表示没有任何引用指向该对象,Python会立即回收该对象所占用的内存。
优点:
- 简单高效,能及时回收不再使用的对象。
- 内存释放的时机是确定的,当引用计数变为零时立即释放。
缺点:
- 无法处理循环引用(即两个或多个对象相互引用,形成一个闭环)。
1 | # 循环引用 |
2. 循环垃圾回收(Cycle Garbage Collection)
为了处理循环引用问题,Python引入了循环垃圾回收机制。Python的垃圾回收器会定期检查对象之间的引用关系,找出无法通过引用计数机制回收的循环引用对象,并将其回收。
Python的循环垃圾回收器主要通过分代回收的方式来提高效率。对象根据其“年龄”被分为三代:
- 第0代:新创建的对象。
- 第1代:经过一次垃圾回收后仍然存活的对象。
- 第2代:经过多次垃圾回收后仍然存活的对象。
垃圾回收器会频繁地检查和回收第0代对象,较少检查和回收第1代对象,更少检查和回收第2代对象。这种分代回收的策略基于“年轻对象更可能是垃圾”的假设,从而提高了垃圾回收的效率。
工作流程:
- 标记阶段:垃圾回收器遍历所有对象,标记出哪些对象是可达的(仍在使用的)。
- 清除阶段:回收所有未标记的对象(不可达的对象)。
3. 手动垃圾回收
虽然Python的垃圾回收机制通常是自动进行的,但也可以通过gc模块手动控制垃圾回收。例如,可以使用以下方法:
gc.collect(): 手动触发垃圾回收。gc.disable(): 禁用自动垃圾回收。gc.enable(): 启用自动垃圾回收。gc.get_count(): 获取当前的引用计数情况。
1 | import gc |
总结
Python的垃圾回收机制主要依赖于引用计数和循环垃圾回收。引用计数负责大部分对象的内存管理,但无法处理循环引用问题;循环垃圾回收则弥补了这一不足,通过分代回收提高了效率。Python还允许开发者通过gc模块手动控制垃圾回收行为。
多线程代码练习
1 |
|
参考
- Title: Linux Basics And Operating System Fundamentals
- Author: LightedCode
- Created at : 2024-08-02 21:19:49
- Updated at : 2024-10-14 09:58:52
- Link: https://lightedcode.github.io/2024/08/02/Linux-Basics-And-Operating-System-Fundamentals/
- License: This work is licensed under CC BY-NC-SA 4.0.